0. Introduction
Overview
Teaching: 10 min
Exercises: 5 minQuestions
1 Does FAIR data mean open data?
2 What are Digital Objects and Persistent Identifiers?
3 Different types of PIDs
Objectives
The participant will understand that the FAIR principles are fundamental for Sustainable Science.
The participant will learn what human and machine-friendly digital objects are.
1. Does FAIR data mean open data?
No.
FAIR means human and machine-friendly data sources which aim for transparency in science and future reuse.
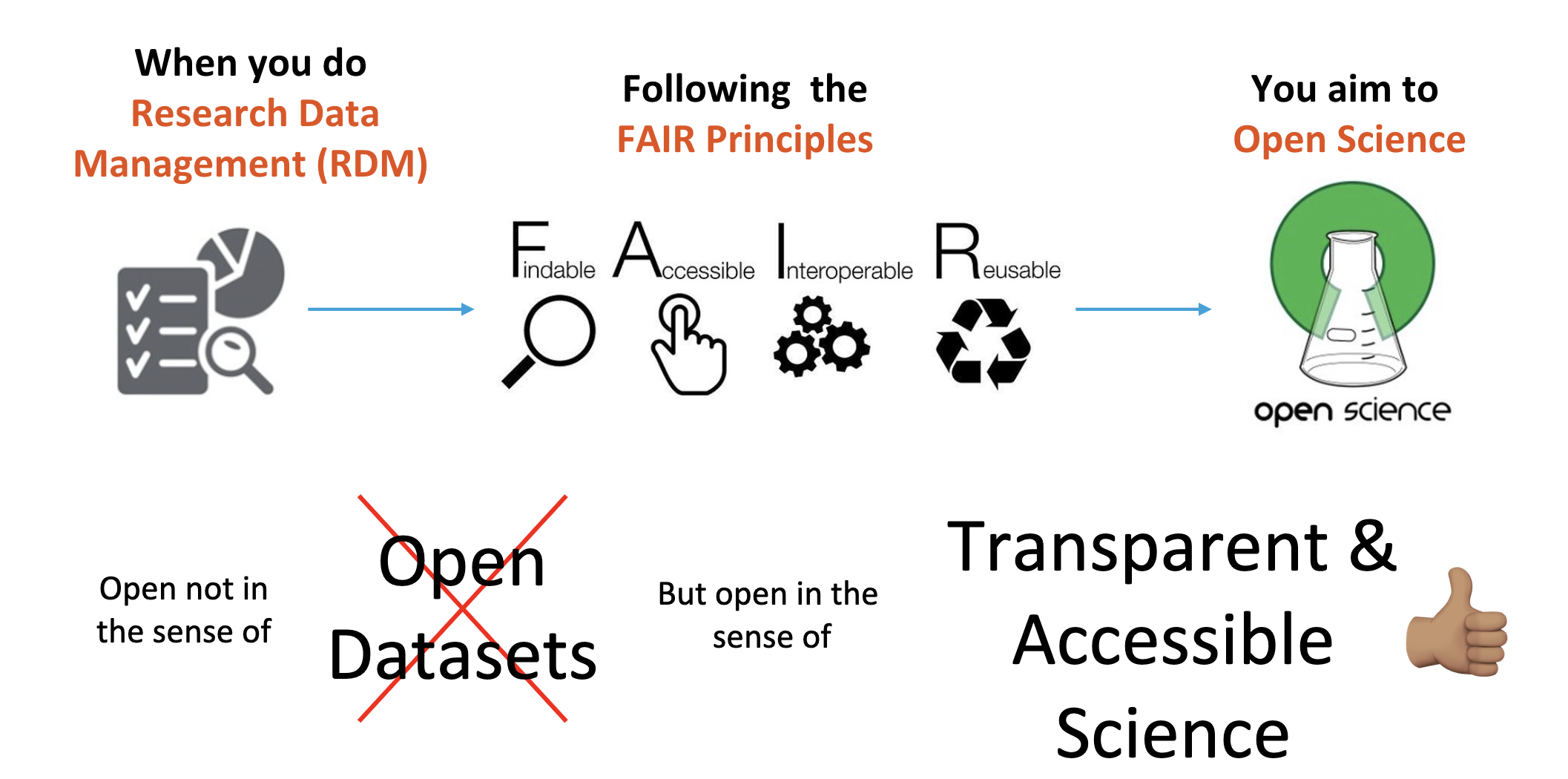
What does it mean to be machine-readable vs human-readable?
Human Readable: “Data in a format that can be conveniently read by a human. Some human-readable formats, such as PDF, are not machine-readable as they are not structured data, i.e., the representation of the data on disk does not represent the actual relationships present in the data.”
Machine Readable: “Data in a data format that can be automatically read and processed by a computer, such as CSV, JSON, XML, etc. Machine-readable data must be structured data. Compare human-readable. Non-digital material (for example, printed or hand-written documents) is not machine-readable by its non-digital nature. But even digital material need not be machine-readable. For example, consider a PDF document containing tables of data. These are definitely digital but are not machine-readable because a computer would struggle to access the tabular information - even though they are very human-readable. The equivalent tables in a format such as a spreadsheet would be machine-readable. As another example, scans (photographs) of text are not machine-readable (but are human-readable!) but the equivalent text in a format such as a simple ASCII text file can be machine-readable and processable.”
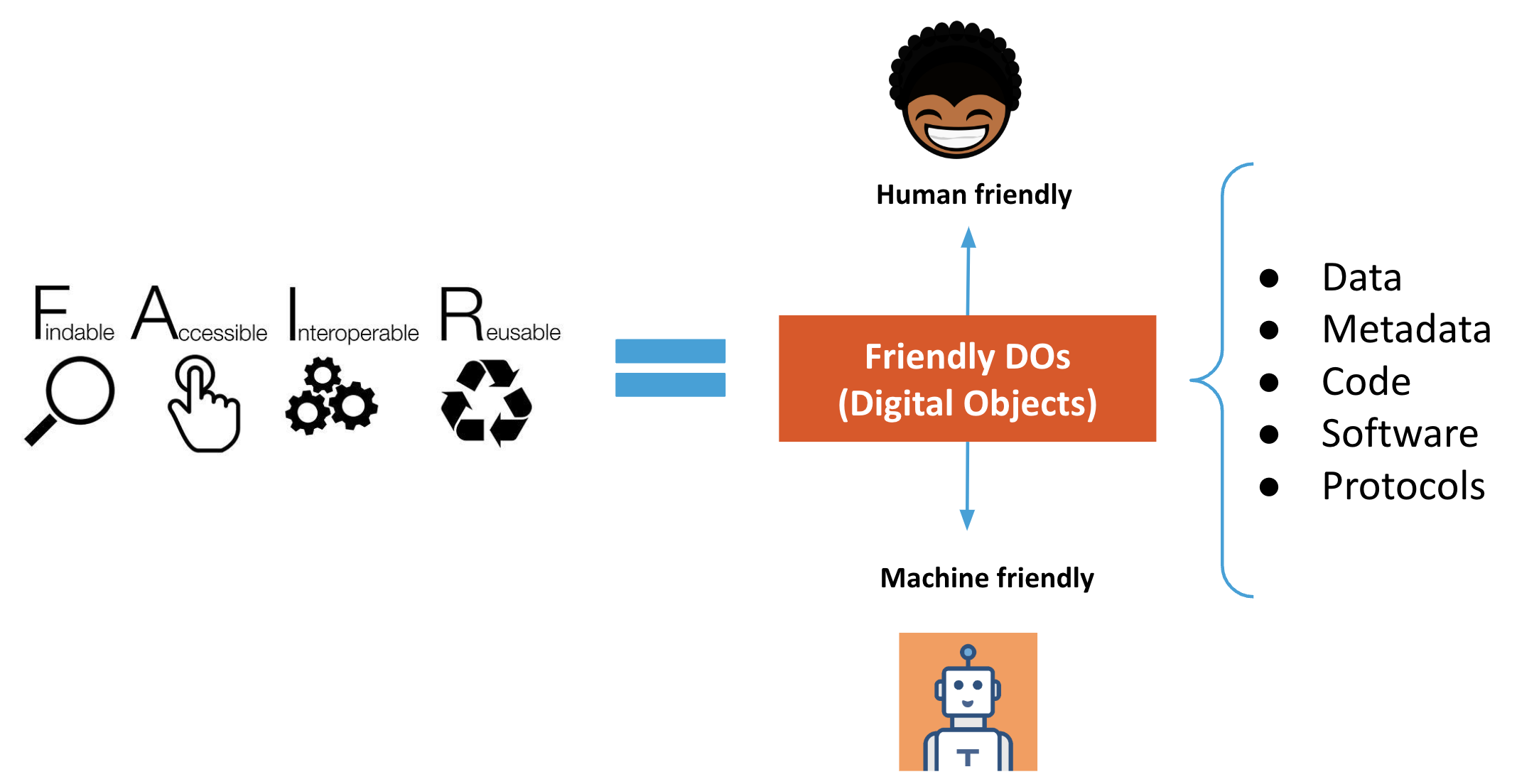
Machine friendly = Machine-readable + Machine-actionable + Machine-interoperable
During this sourcebook, we will be using “Machine-readable” and “Machine friendly” interchangeably. We like the term “friendly” since it can also include “machine-actionability” and “machine-interoperability.”
2. What are Digital Objects and Persistent Identifiers?
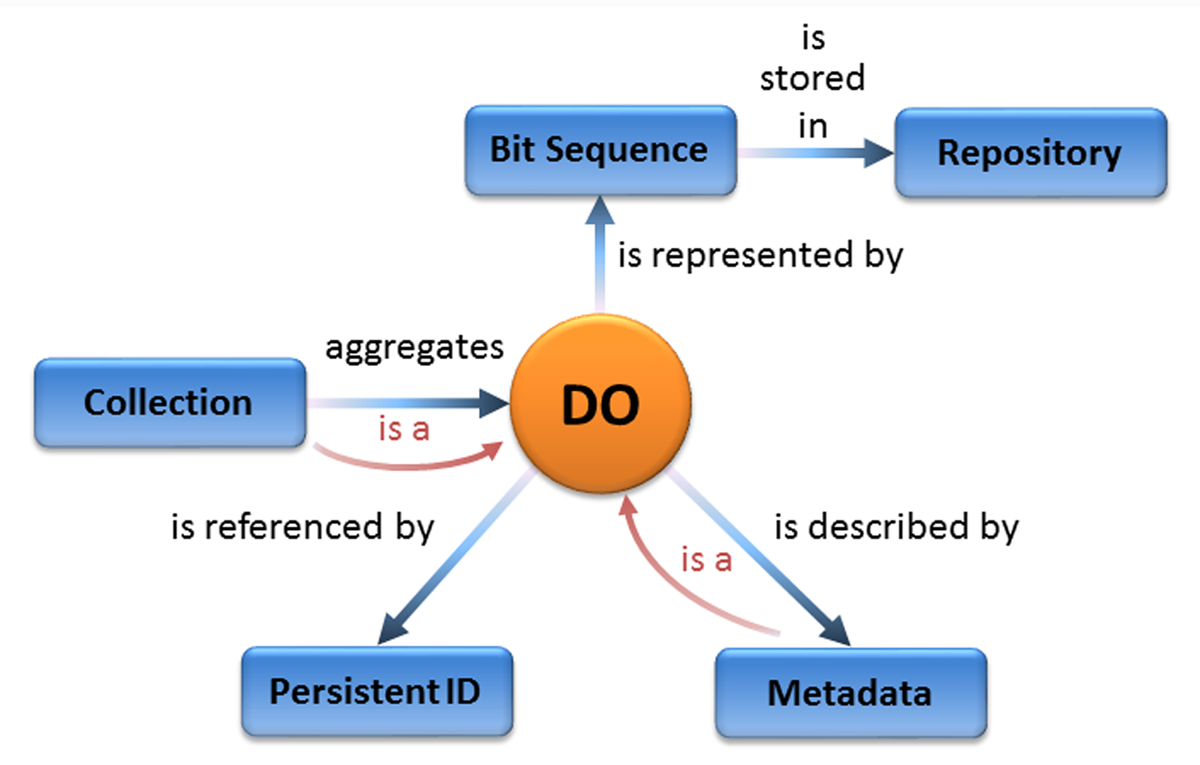
A Digital Object is a bit sequence located in a digital memory or storage that has, on its own, informational value. For example:
- A Scientific Publication
- A Dataset
- A Rich Metadata file
- A README file containing Terms of use & Access Protocols
To learn more about FAIR Digital Objects
FAIR Digital Objects: Which Services Are Required? (Schwardmann, Ulrich 2020) FAIR Digital Object Framework Documentation (BdSS, Luiz Olavo 2020)
A Persistent Identifier (PID) is a long-lasting reference to a (digital or physical) resource:
- Designed to provide access to information about a resource even if the resource it describes has moved location on the web
- Requires technical, governance, and community support to provide the persistence
- There are many different PIDs available for many different types of scholarly resources, e.g., articles, data, samples, authors, grants, projects, conference papers, and so much more
Video: The FREYA project explains the significance of PID: LINK TO SOURCE
Different types of PIDs
PIDs have community support, organizational commitment, and technical infrastructure to ensure the persistence of identifiers. They are often created to respond to a community’s needs. For instance, the International Standard Book Number or ISBN was created to assign unique numbers to books, is used by book publishers, and is managed by the International ISBN Agency. Another type of PID, the Open Researcher and Contributor ID or ORCID (iD), was created to help with author disambiguation by providing unique identifiers for authors. The ODIN Project identifies additional PIDs along with Wikipedia’s page on PIDs.
In Episode 6 (Data Archiving), you will explore one type of PID, the DOI (Digital Object Identifier), which is usually the standard PID for Datasets and Publications.
Exercise - Level Easy 🌶
- arXiv is a preprint repository for physics, math, computer science, and related disciplines.
- It allows researchers to share and access their work before it is formally published.
- Visit the arXiv new papers page for Machine Learning.
- Choose any paper by clicking on the ‘pdf’ link. Now use control + F or command + F and search for ‘HTTP’. Did the author use DOIs for their data?
Solution
Authors will often link to platforms such as GitHub where they have shared their software, and/or they will link to their website hosting the data used in the paper. The danger is that platforms like GitHub and personal websites are not permanent. Instead, authors can use repositories to deposit and preserve their data and software while minting a DOI. Links to software sharing platforms or personal websites might move, but DOIs will always resolve to information about the software and/or data. See DataCite’s Best Practices for a Tombstone Page.
DOIs are everywhere, examples:
- Resource IDs (articles, data, software, …)
- Researcher IDs
- Organization IDs, Funder IDs
- Project IDs
- Instrument IDs
- Physical sample IDs,
- DMP IDs…
- Media: videos, images, 3D models
How does your discipline share data?
Does your discipline have a data journal? Or some other mechanism to share data? For example, the American Astronomical Society (AAS), via the publisher IOP Physics, offers a supplement series as a way for astronomers to publish data.
Key Points
FAIR means human and machine-friendly data sources which aim for transparency in science and future reuse.
DOI (Digital Object Identifier) is a type of PID (Persistent Identifier)
1. Set up your own terms
Overview
Teaching: 10 min
Exercises: 15 minQuestions
1 What are Data Terms of Use?
2 What must a Data Terms of Use statement contain?
3 What format should Data Terms of Use be?
4 Are there standard Licenses we can pick from?
Objectives
The participant will understand what data terms of use are with examples.
The participant will be able to create basic data terms of use.
FAIR principles used in Data Terms of Use:
Accessible
FM-A2 (Metadata Longevity) → doi.org/10.25504/FAIRsharing.A2W4nz
Reusable
FM-R1.1 (Accessible Usage License) → doi.org/10.25504/FAIRsharing.fsB7NK
1 What are Data Terms of Use?
Data Terms of Use is a textual statement that sets the rules, terms, conditions, actions, legal considerations, and licenses that delineate data use.
An example is:

The World Bank - Terms of Use for Datasets → LINK TO EXAMPLE
Looking at the example, we can identify general elements in the Data Terms of Use statement. For instance, a broad description of the data is referred to, but also under what type of license the user is allowed to reuse.
Sometimes as part of our research, we use commercial databases. We should be careful always to read the conditions for using it for research purposes.
An example is:

Terms of Use - Numbeo.com → LINK TO EXAMPLE
We can see that clause 3 of Licensing of content requests work attribution.
2 What must a Data Terms of Use statement contain?
As a general rule, a Data Terms of Use statement must contain at least the following:
| Section | Description | Example |
|---|---|---|
| Description | What is this statement about and what Digital Objects are referred to | The following Terms of Use statement is about my happy dataset |
| License | Statement under which conditions a requester is allowed to use the data source | The happy dataset is of Public Domain |
| Work attribution | Statement requesting citation of the data source used | Could you please cite my happy dataset? |
| Disclaimer | Any consideration that the requester should be aware of | The last 100 records of my happy dataset might have selection bias |
Nevertheless, depending on the use case, the “Data Terms of Use” statement can be extended by adding specific clauses when complex data, multiple databases, or sensitive data are involved. After all, the “Data Terms of Use” statement is the legal basis of the referred data source. i.e., in the light of public law, you can make someone liable for not complying with specific clauses of the statement.
Moreover, sometimes our work is conducted within the context of a greater scientific funded project. Therefore, it is always recommended to check with the Principal Investigator or Project Manager whether the Data Terms of Use statement is to be defined or if there is already a Data Policy framework.
An example is:
Policy for use and oversight of samples and data arising from the Biomedical Resource of the 1958 Birth Cohort (National Child Development Study) → LINK TO EXAMPLE
- Link to the original Data Policy
This policy framework creates comprehensive guidelines on handling data for that specific study involving children’s data. Therefore, the researchers working underneath the project do not have to make new Data Terms of Use.
“Data Terms of Use” statement is the legal basis of the referred data source
In the light of public law, you can make someone liable for not complying with specific clauses of the statement.
3 What format should Data Terms of Use be?
The Data Terms of Use is a plain text statement. This text has the length and depth that the data owner or data manager sees fit. There is no right or wrong when drafting it. Usually, it is recommended to store this textual statement in a README file, using an accessible format, for example, .txt, .md, or .html so that any user can read it without needing any additional software.
The Data Terms of Use is a plain text statement written in a machine-friendly format
The “Data Terms of Use” can be drafted using any application (e.g., MS Word). However, it’s important to store it in a machine-friendly format such as
.txtor.md
Any text editor software would do the trick, such as Notepad++ or Sublime Text, but also you can write it using Microsoft Word or Google Docs and save it as .txt
Exercise - Level Medium 🌶🌶
- Visit the landing page of the following terms of use github.com/CityOfPhiladelphia/terms-of-use/blob/master/LICENSE.md
- Can you tell what type of data it is about?
- Can you tell in what format the terms of use are written?
- What platform are they using to put it?
Solution
- Refers to the public code on which the large city of Philadelphia government is based (https://www.phila.gov/)
- The format is Markdown (
.md)- They used Github to put the
LICENSE.mdfile, which is the Data Terms of Use.
The Data Terms of Use needs to be in the same root folder as the data source. When it comes to a database - like the World Bank example - it should be findable on the project’s website. Moreover, if there is no official project website, you should include it in .md format in a Github repository like the following example: → LINK TO EXAMPLE

In Episode 4 (Data Archiving), we will explore that some data repositories such as DataverseNL allow you to create a Data Terms of Use statement directly on the platform when you create a data project.
By default, you get a waiver License CC0 “No Rights Reserved”. Putting a database or dataset in the public domain under CC0 is a way to remove any legal doubt about whether researchers can use the data in their projects. Although CC0 doesn’t legally require data users to cite the source, it does not affect the ethical norms for attribution in scientific and research communities. Moreover, you can change this waiver to a tailored Terms of Use you have created for your data.

Exercise - Level Easy 🌶
Is it possible to edit the Terms of Use in DataverseNL?
Go to DataverseNL/ to the FAQ section to find out.
Solution
Yes, it is possible. However, you can’t choose it at the beginning. After creating a dataset, go to the ‘Terms’ tab on your dataset page and click ‘Edit Terms requirements’. Next, select the radio button ‘No, do not apply CC0 public domain dedication’, and fill in the text fields with your terms and conditions.
Dataverse also provides Sample Data Usage Agreement → LINK
4 Are there standard Licenses we can pick from?
Yes, there are two general License frameworks that can work for data.
Creative Commons (CC) provides several licenses that can be used with a wide variety of creations that might otherwise fall under copyright restrictions, including music, art, books, and photographs. Although not tailored for data, CC licenses can be used as data licenses because they are easy to understand. Its website includes a summary page HERE outlining all the available licenses, explained with simple visual symbols.
| Permission Mark | What can I do with the data? |
|---|---|
| BY | Creator must be credited |
| SA | Derivatives or redistributions must have an identical license |
| NC | Only non-commercial uses are allowed |
| ND | No derivatives are allowed |
Open Data Commons (ODC) provides three licenses that can be explicitly applied to data. The web pages of each of these licenses include human-readable summaries, with the ramifications of the legalese explained in a concise format.
Exercise - Level Easy 🌶
Pick a License at creativecommons.org with the following conditions:
- Others cannot make changes to the work since it’s simulation data
- If someone wants to use the simulation data for a startup, they can Question: What type of license is it?
Solution
Attribution-NoDerivatives 4.0 International
Discussion
Scenario:
You are a sociology and statistics researcher, and now you are collaborating with a researcher from the hospital. Your collaborator researches Children’s Mental Health. You will combine expertise and conduct a study on the Quality of Life in Children. In addition, you will lead a national survey in Dutch schools. You are thinking of collecting information about bullying, social media, and family structure.Discuss with your team what considerations need to be taken into account when drafting a Data Terms of Use for this study. Do you think a legal expert must write the terms of use, or can it be done by the researchers?
Key Points
The Data Terms of Use statement is the legal basis of the referred data source.
A License is the bare minimum requirement for Data Terms of Use.
If a standard License does not fit your project, then you can use Terms of Use layouts e.g. Sample Data Usage Agreement.
2. Speak the same language
Overview
Teaching: 10 min
Exercises: 15 minQuestions
1 What are Data Descriptions?
2 How to reuse Data Descriptions?
3 Are there standard ways for doing Data Descriptions?
4 What is the relation between Data Descriptions and Linked Data?
Objectives
The participant will learn that Data Descriptions are named differently in various fields.
The participant will be able to create a machine-friendly Data Descriptions file.
FAIR principles used in Data Descriptions:
Interoperable
FM-I1 (Use a Knowledge Representation Language) → doi.org/10.25504/FAIRsharing.jLpL6i
FM-I2 (Use FAIR Vocabularies) → doi.org/10.25504/FAIRsharing.jLpL6iReusable
FM-R1.3 (Meets Community Standards) → doi.org/10.25504/FAIRsharing.cuyPH9
1. What are Data Descriptions?
Data descriptions are a detailed explanation and documentation of each data attribute or variable in a dataset.
Depending on the use case and field of research, these data descriptions are also known as:
- Codebooks (e.g., in Statistics or Social Sciences)
- Data Dictionaries (e.g., in Computer and Data Science)
- Labels or Data Tags (e.g., in Crowdsourcing or Humanities)
- Data Glossary (e.g., in Business Administration & Finance)
- Metadata (wrong use of this term in this context)
For example:
| Variable Name | Description | Scale |
|---|---|---|
| Weight | Weight of a human | kilograms |
| Height | Height of a human | centimetres |
| Age | Age of a human | years |
| Blood Glucose Level | Blood glucose level of a human | mg/dl |
“Data Descriptions” is sometimes named differently depending on the field
No matter what terminology you use, “Data Descriptions” always refers to a detailed explanation and documentation of each data attribute or variable in a dataset.
2. How to reuse Data Descriptions?
Documentation of any kind always takes time. However, we shall always aim to reuse existing data descriptions generally accepted in the community. i.e., the variable Weight is a concept that has been widely used in research; therefore, we don’t need to redefine it every time.
For example, in BioPortal, we can find existing descriptions of Weight. These descriptions belong to an Ontology, i.e., a community-accepted online dictionary for curated terms and definitions. Moreover, it provides a globally unique identifier to the description. → LINK TO EXAMPLE
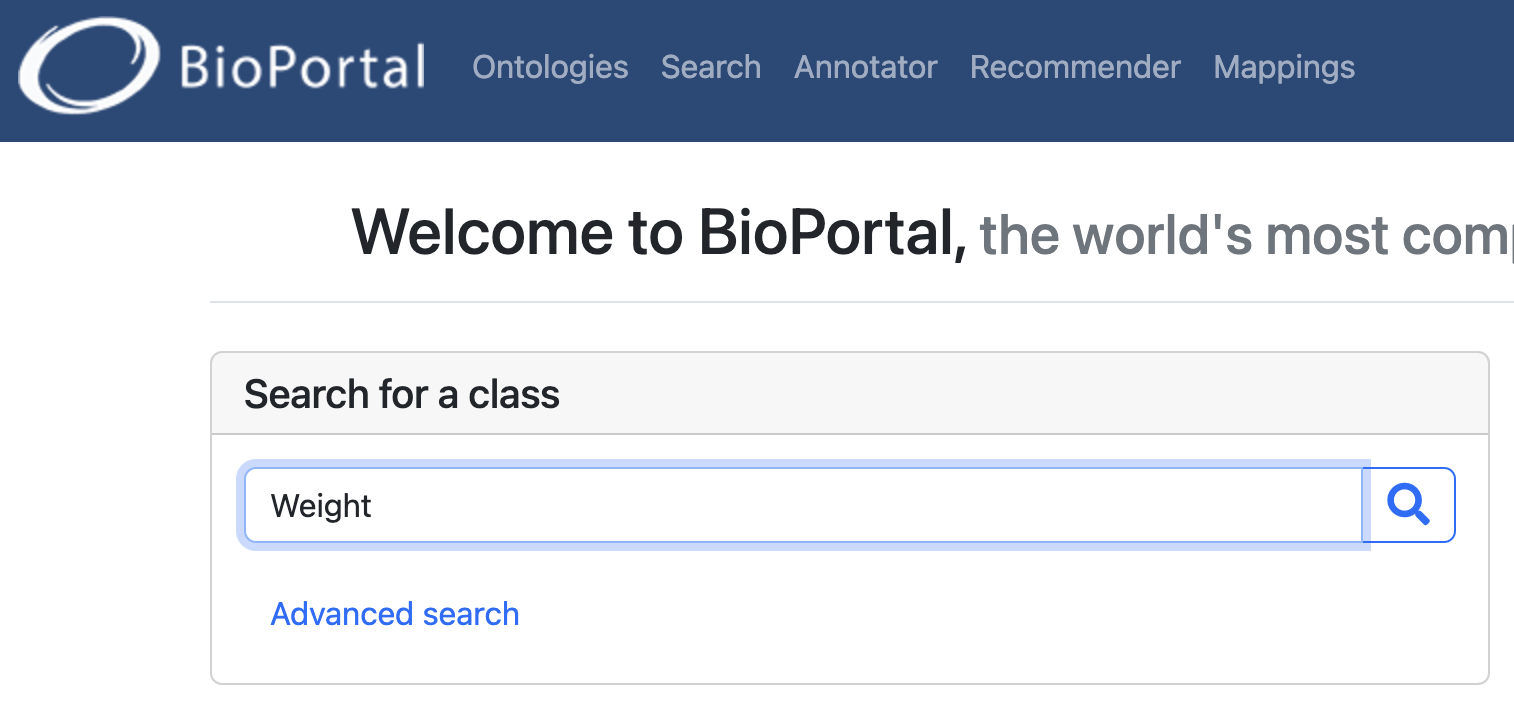
You will get several results when searching for a term and its definition. These results regard the different ontologies that define these terms. For example, think of the description of an apple. It might be defined differently in a British dictionary than in an American one.
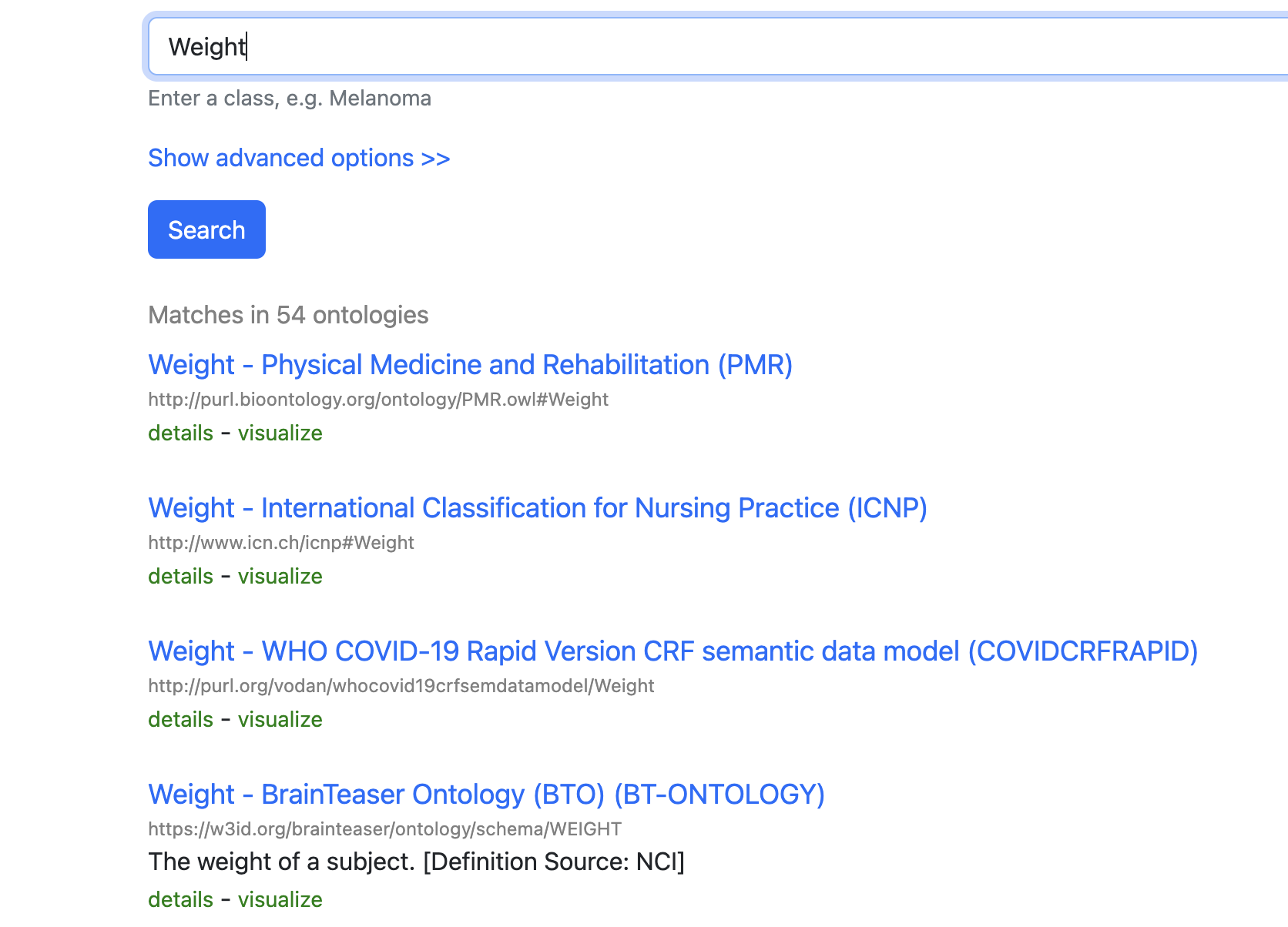
Finally, using this Ontology, you can get a standard definition that community experts curate has a global identifier.

Describe your data by reusing Ontology terms
By reusing Ontology terms or community-accepted vocabularies, we aim to create a culture of recycling definitions by default.
Advantages
- We don’t have to redefine the terms every time
- We get a permanent link to the resource
- Since it uses a global identifier becomes easier for others to integrate with different data sources
Disadvantages- Sometimes, you might not find an Ontology or vocabulary that fits your variable.
3. Are there standard ways for doing Data Descriptions?
There are no standard ways of doing Data Descriptions.
The minimum elements you need to describe your dataset are the Variable Name and the Link to Description. You can do that in a tabular format. However, following the FAIR principles of Interoperability and Reusability, we must ensure that the data is described using community standard FAIR vocabularies. Here are some Ontologies for general use that can cover a wide variety of data attributes
| Ontology | Link | About what? |
|---|---|---|
| Schema.org | LINK | Definitions of generic things e.g., “Computer” |
| DBpedia | LINK | Definitions from Wikipedia |
| Data Catalog Vocabulary (DCAT) | LINK | Definitions about data things e.g., “accessURL” |
| Dublin Core | LINK | Definitions about Metadata |
There are also public registries where you can find Ontologies
Linked Open Vocabularies → lov.linkeddata.es/dataset/lov/
EU Vocabularies: → op.europa.eu/en/web/eu-vocabularies
BioPortal: → bioportal.bioontology.org/
AgroPortal: → agroportal.lirmm.fr/
EcoPortal → ecoportal.lifewatchitaly.eu/
Ontology Lookup Service by the EBI → ebi.ac.uk/ols/index
Bioschemas → bioschemas.org/
Exercise - Level Easy 🌶
- Visit BioPortal. BioPortal is the most known repository for biomedical ontologies
- Search for an Ontology term for
blood glucose levelIn the “Search for a class” search box.- Select one result related to a clinical measurement that is sound to you.
- What are the definition and ID?
Solution
Definition: Measurement of the amount of glucose, the monosaccharide sugar, C6H12O6, occurring widely in plant and animal tissues which is one of the three dietary monosaccharides that are absorbed directly into the bloodstream during digestion, is the end product of carbohydrate metabolism, and is the chief source of energy for living organisms, in a specified volume of blood, the fluid that circulates through the heart, arteries, capillaries and veins carrying nutrients and oxygen to the body tissues and metabolites away from them.
ID: http://purl.obolibrary.org/obo/CMO_0000046
The Data Descriptions (or data dictionaries in some domains) are usually manually written in a tabular format. This document has the length and depth that the data owner sees fit. The general rule of thumb is to describe the dataset related to a publication. Any accessible format like .csv, .xls, or similar is acceptable.
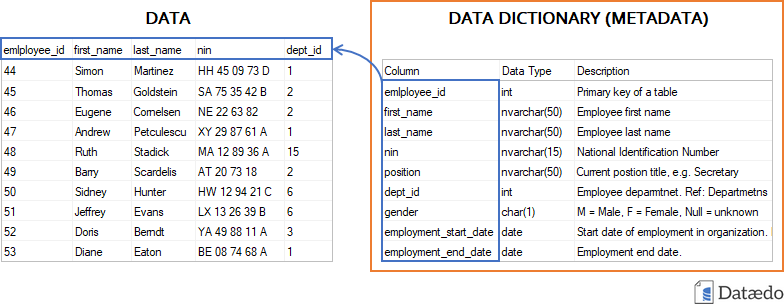
In case it is a database, a data model must be included in machine-readable format (e.g., .sql) and a human-friendly diagram (e.g., ER model on .pdf).
There are examples where data descriptions are made available in a human-relatable manner, such as the dataset nutrition labels style (Holland et al., 2018).
An example is A Statutory Article Retrieval Dataset → LINK TO EXAMPLE
Moreover, there are tools and software packages to generate automated “Codebooks” by only looking at the dataset
An example is Automatic Codebooks from Metadata Encoded in Dataset Attributes → LINK TO EXAMPLE.
{kind=link}
These initiatives are helping us standardize data descriptions and are “Human Friendly”, which works perfectly. However, the FAIR principles FM-I1, FM-I2 and FM-R1.3 explicitly mention the need for Linked Data formats in order to gain the maximum level of Interoperability.
4. What is the relation between Data Descriptions and Linked Data?
When we create comprehensive Data Descriptions reusing terminologies of existing Ontologies, we could make available our dataset in a Linked Data format which makes it Interoperable with other datasets out there.
Imagine your dataset can be helpful to another researcher in the future. The future researcher can reuse your dataset and combine both by matching variable names with the Ontology identifiers.
There are several tools that help you to convert your dataset from a conventional format into a Linked Data format (e.g., RDF format).
| Tool | Source | GUI | Note |
|---|---|---|---|
| Open Refine | LINK | ✅ | Installation can be a hassle and takes a lot of memory |
| RMLmapper | LINK | ❌ | Highly technical you need to know command line tools, preferred option of data engineers |
| SDM-RDFizer | LINK | ❌ | You need to be familiar with programming languages |
| SPARQL-Generate | LINK | ✅ | It is a good option if you are going to invest time in it since you can learn SPARQL language |
| Virtuoso Universal Serve | LINK | ✅ | It’s nice but you have to pay for a license |
| UM LDWizard | LINK | ✅ | It’s free, gets the job done quickly, and you can publish data if you have a TriplyDB account → RECOMMENDED |
Exercise - Level Hard 🌶🌶🌶
Transform a dataset from XLSX format to RDF format using UM LDWizard
Download the following mock dataset: MOCK DATA
What ontology terms did you reuse to describe the data attributes?
Solution
There is no one single answer 🤓
Discussion
Scenario:
You are a marine biology researcher, your group has discovered new organisms, and it’s time to create data descriptions. However, there are no available Ontologies to describe the data records, given that they are new scientific discoveries.Discuss with your team what the researcher should do given that apparently there are no available Ontologies to describe their data.
Key Points
‘Codebook’, ‘data glossary’, or ‘data dictionary’ are some other ways to name Data Descriptions.
Ontologies (in information science) are like public online vocabularies of community curated terms and their definitions.
By reusing Ontology terms or community accepted vocabularies, we aim to create a culture of recycling terminology by default.
3. Securely share
Overview
Teaching: 10 min
Exercises: 15 minQuestions
1 What are data access protocols?
2 Is Open Access a data access protocol?
3 Can I expose my data as a service using FAIR API protocols?
Objectives
The participant will learn what data access protocols are.
The participant will explore the aspects of an access protocol for humans and machines.
FAIR principles used in Data Access Protocols:
Accessible
FM-A1.1 (Access Protocol) → doi.org/10.25504/FAIRsharing.yDJci5
FM-A1.2 (Access Authorization) → doi.org/10.25504/FAIRsharing.EwnE1nInteroperable
FM-I3 (Use Qualified References) → doi.org/10.25504/FAIRsharing.B2sbNh
1. What are Data Access Protocols?
Data Access Protocols are a set of formatting and processing rules for data communication. In practice, Data Access Protocols are the explicit instructions for humans and machines to access a data source.
Imagine you enter a security room. You need to follow specific steps or possess specific keys for accessing the room. The same is with data. Moreover, if the door of the room is open we can say it is Open Access.

Following the premise that “Data Access Protocols” are a common set of rules in a standard language, they exist in various ranges. For example, some messages are directed to humans, and some protocols are meant for machines.
| Access Protocol | Example | Note |
|---|---|---|
| Communication between machines | 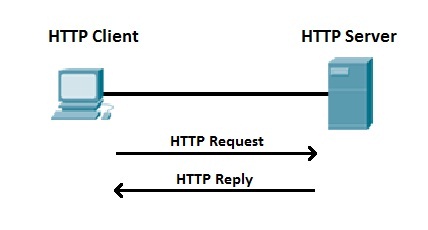 |
A PC requesting information using HTTP protocol |
| Communication between humans |  |
Data owner requesting users to contact directly for data access |
Image: Mapping EU Company Mobility & Abuse-Detection → LINK TO EXAMPLE
In a strict sense, data access protocols relate to network protocol definitions. However, regarding Research Data, the human factor plays a part. Therefore, we can explicitly mention the rules and instructions for accessing data depending on the use case. Sometimes the data can’t be publicly available, and there is no particular repository for it. Therefore, you request the user to contact you to get access. We could say it is a human-friendly access protocol.
For example:
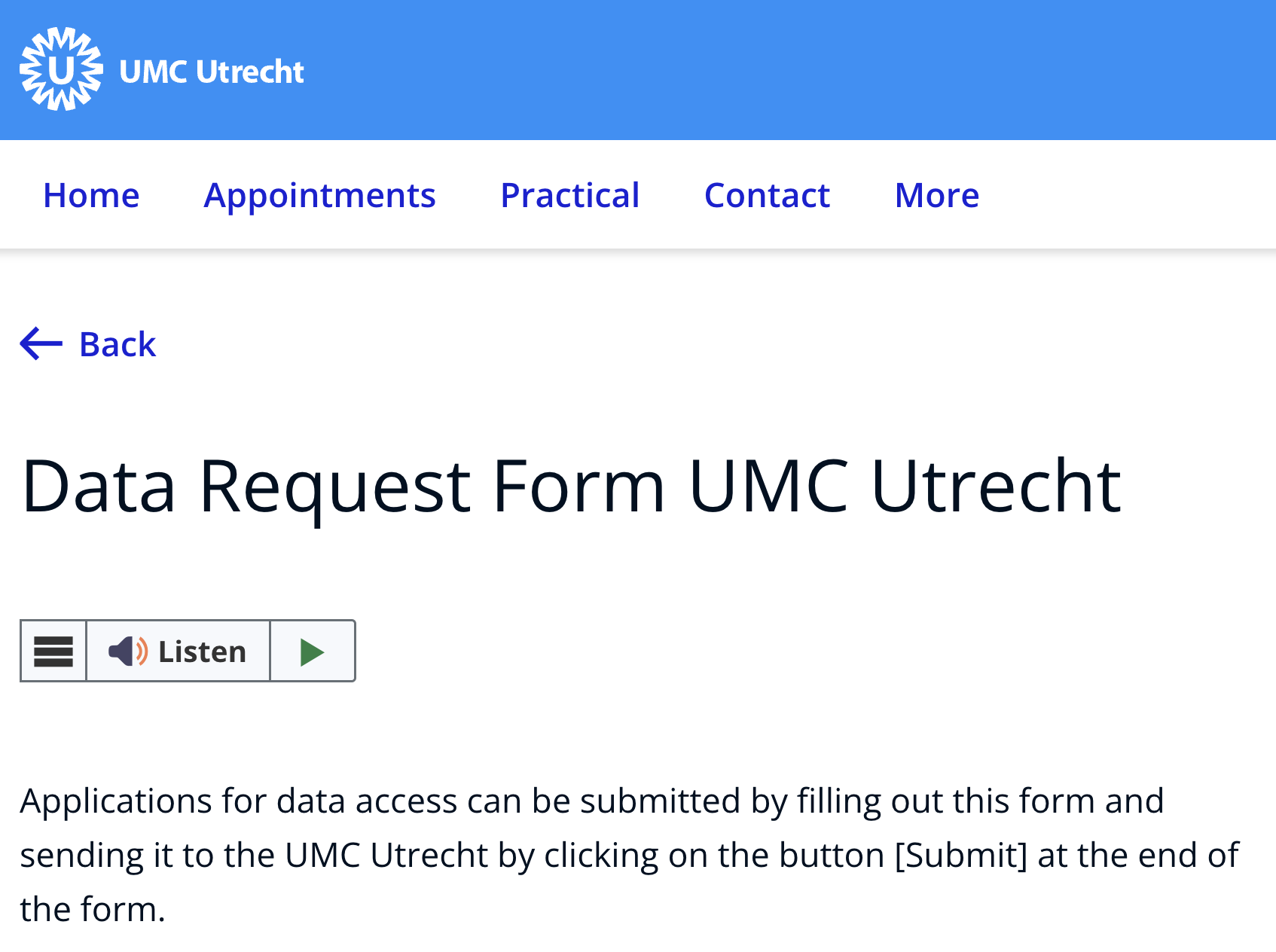
In Data Request Form UMC Utrecht → LINK TO EXAMPLE
The University Medical Center at Utrecht (UMC Utrecht) has an open data request form for users to access clinical data for research purposes. The form asks general things related to the researcher’s identification and affiliation, research context, and methodologies. Furthermore, they explicitly mention that the Data Access Committee will review and consider applications and respond within 4 weeks.
Protocols are like standard rules communicated in a standard language for humans and machines.
We humans predominantly use the English language for communication in science.
Likewise, Machines need a “medium” to talk to each other such as an API (Application Programming Interface), and they use a “communication language” such as HTTP Hypertext Transfer Protocol to share information between one another.
Relevant API protocols are:
2. Is Open Access a data access protocol?
Open Access is a policy framework in the strict sense but yes! We could say it’s a data access protocol. Within the Open Science recommendations, it is endorsed to standardize open access datasets when it is possible to make them publicly available and does not violate legal or ethical considerations. More information at Open Access.
![]()
Depositing datasets in public data repositories can grant them open access protocol automatically. In addition, data repositories typically work as a data archiving instrument, which we cover in Episode 6 (Data Archiving).
Moreover, Open Access data sources can be made available using FAIR protocols such as SPARQL API endpoints.
An example is:
The European Union Public Data → LINK TO EXAMPLE
Which makes available all public datasets. The following endpoint (permanent link) https://data.europa.eu/sparql
Exercise - Level Easy 🌶
- Go to ZENODO Covid 19 Community.
- Can you tell what is the default “Data Access Protocol” for the Digital Objects displayed?
Solution
It is Open Access. It is indicated in the green tag on top of the titles.
Open Access is a human and machine-friendly Data Access Protocol
Humans see a “Download” button
Machines see an HTTPS request
3. Can I expose my data as a service using FAIR API protocols?
Yes, it is possible; however, it is not an easy road and requires technical skills.
We must remember that exposing data as a service would mean we need a server to host it, which we don’t always have. Moreover, one of the main motivations to expose our data using FAIR protocols is to make it accessible for other data sources to integrate. But for that, you would need some basic understanding of Knowledge Graphs technologies. More information about this can be found in the FAIR Elixir Cookbook.
| Tool | Source | GUI | Note |
|---|---|---|---|
| TriplyDB | LINK | ✅ | Free account, you can expose your data on their servers for a limited time |
| GraphDB | LINK | ✅ | Nice interface; you need to rely on a server |
| FAIR Data Point | LINK | ❌ | Highly technical, requires programming language knowledge |
| RDFlib Endpoint | LINK | ❌ | Requires familiarity with terminal, but is the quickest way to get started |
Important!
When you expose your data using FAIR API protocols, you must register your service in a registry for FAIR APIs such as SMART API
Exercise - Level Hard 🌶🌶🌶
- Expose your RDF data to a service endpoint using a FAIR API protocol
- Use the RDF data you generated in Episode 2 (data descriptions) else you can download it here
- In your terminal, install the following library using the default Python installation
pip install rdflib-endpoint@git+https://github.com/vemonet/rdflib-endpoint@main- Next, execute the following command to locally expose your data
rdflib-endpoint serve data-file.ntSolution
This exercise is optional
Discussion
Scenario:
You are a researcher of Sustainable Investment from the Economics department. After your research, you ended up possessing sensitive financial information of company figures that cannot be disclosed since competitors could misuse this information. You will store the data in a secure environment but you would like to make it available for research purposes.
Note: The data is not about personal data.Discuss with your team what type of access protocols shall be considered in this case.
Key Points
Data Access Protocols are a set of formatting and processing rules for data communication. For example, imagine you enter a security room. You must follow certain steps or possess keys to access the room.
When you expose your data using FAIR protocols, you must register your service in a registry for FAIR APIs such as SMART API.
4. Publish and preserve
Overview
Teaching: 10 min
Exercises: 15 minQuestions
1 What is Data Archiving?
2 What are Data Repositories?
3 What is a DOI, and why is it important?
Objectives
The participant will understand the importance of archiving datasets on trusted data repositories.
The participant will learn the significance of the Digital Object Identifier (DOI).
FAIR principles used in Data Archiving
Findable
FM-F1A (Identifier Uniqueness) → doi.org/10.25504/FAIRsharing.r49beq
FM-F3 (Resource Identifier in Metadata) → doi.org/10.25504/FAIRsharing.o8TYnWAccessible
FM-A2 (Metadata Longevity) → doi.org/10.25504/FAIRsharing.A2W4nz
1. What is Data Archiving?
“Data Archiving” is the practice of placing a digital source in a preservation phase, i.e., the long-term storage of research data.
The various academic journals have different policies regarding how much of their data and methods researchers are required to store in a public archive. Similarly, the major grant-giving institutions have varying attitudes toward public archival of data. In general, publications must have attached sufficient information to allow fellow researchers to replicate and test the research.
2. What are Data Repositories?
Datasets are archived in Data repositories. They are storage locations for digital objects. Data repositories can help make a researcher’s data more discoverable by search engines (e.g., Google) and ultimately lead to potential reuse. Therefore, using storage can lead to increased citations of your work. Data repositories can also serve as backups during rare events where data are lost to the researcher and must be retrieved.
Note
Data Archiving is the long-term storage of research data. Data repositories can help make research data more discoverable by search engines (e.g., Googlebots).
Examples of data repositories:
| Data Repository | About |
|---|---|
| DataverseNL | DataverseNL is a community-specific repository that focuses on Dutch universities and research centers. |
| 4TU Data | 4TU Data is a community repository that was originally created by three technical universities in the Netherlands. |
| PANGEA | PANGEA is a community-specific repository that focuses on Earth & Environmental Science. |
| FigShare | FigShare is an open generic data repository for general purposes; it can store data and other digital objects. |
Just like FigShare, many data repositories are for general use. They provide a low entry barrier to making data Findable, addressing FM-F1A (Identifier Uniqueness) and FM-F3 (Resource Identifier in Metadata).
Recommendations for general-purpose data repositories
ZENODO administrated by CERN
SURF Repository administrated by SURF
DataverseNL administrated by DANS
Quick characteristics of general-purpose repositories:
- Safe — your research is stored safely for the future in a Data Centre for as long as CERN and/or DANS exist.
- Citeable — every upload is assigned a Digital Object Identifier (DOI) to make them citable and trackable.
- No waiting time — Uploads are made available online as soon as you hit publish, and your DOI is registered within seconds.
- Open or closed — Share, e.g., anonymized clinical trial data with only medical professionals via our restricted access mode.
- Versioning — Easily update your dataset with our versioning feature.
- GitHub integration — Easily preserve your GitHub repository in Zenodo.
- Usage statistics — All uploads display standards-compliant usage statistics.
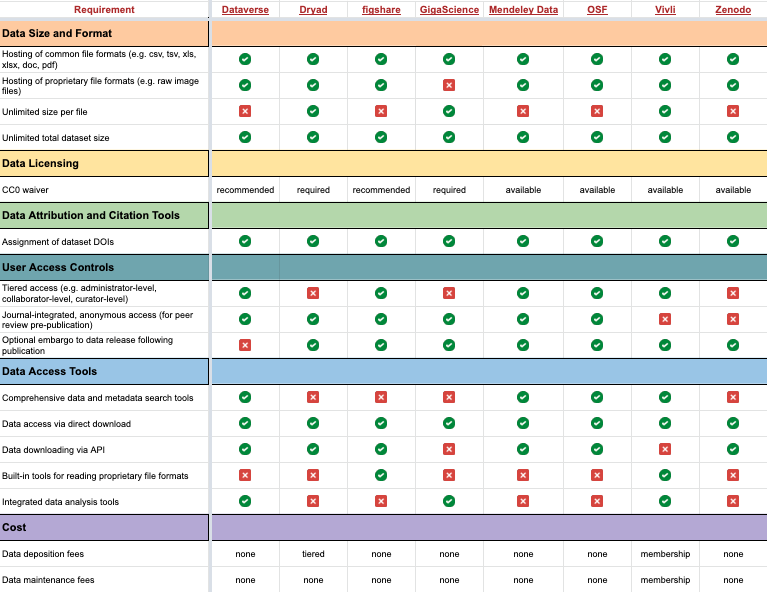 Image: Harvard Medical School, RDM - Data Repositories. Accessed Jul-2022 - *datamanagement.hms.harvard.edu/share/data-repositories
Image: Harvard Medical School, RDM - Data Repositories. Accessed Jul-2022 - *datamanagement.hms.harvard.edu/share/data-repositories
Original Harvard Dataverse
Some public registries where you can find lists of trusted repositories for Data Archiving
Registry of Research Data Repositories (re3data) → re3data.org//
PLOS ONE Recommended Repositories → journals.plos.org/plosone/s/recommended-repositories
NIH Recommended Repositories: → sharing.nih.gov/repositories-for-sharing-scientific-data
Nature - Scientific Data Guidelines: → nature-com.mu.idm.oclc.org/sdata/policies/repositories
OpenDOAR - Directory of Open Access Repositories → v2.sherpa.ac.uk/opendoar/
Exercise - Level Medium 🌶🌶
- Go to dataverse.org and scroll down until you see a map. Respond to the following:
- How many installations of Dataverse are there?
- How many Dataverse installations are in the Netherlands?
- DataverseNL is the data repository hosted by DANS. It supports all higher education institutions in the Netherlands. How many datasets exist now in DataverseNL? (Aug 2022)
Solution
- There are 83 installations worldwide. This means that 83 organizations have a copy of the original Harvard Dataverse layout and have hosted it on their own servers to support researchers.
- There are 3 installations in the Netherlands: DataverseNL, IISH Dataverse, and NIOZ Dataverse.
- There are 6,075.
3. What is a DOI, and why is it important?
The DOI is a common identifier used for academic, professional, and governmental information such as articles, datasets, reports, and other supplemental information. The International DOI Foundation (IDF) is the agency that oversees DOIs. CrossRef and DataCite are two prominent not-for-profit registries that provide services to create or mint DOIs. Both have membership models where their clients are able to mint DOIs distinguished by their prefix. For example, DataCite features a statistics page where you can see registrations by members.
A DOI has three main parts:
- Proxy or DOI resolver service
- Prefix which is unique to the registrant or member
- Suffix, a unique identifier assigned locally by the registrant to an object
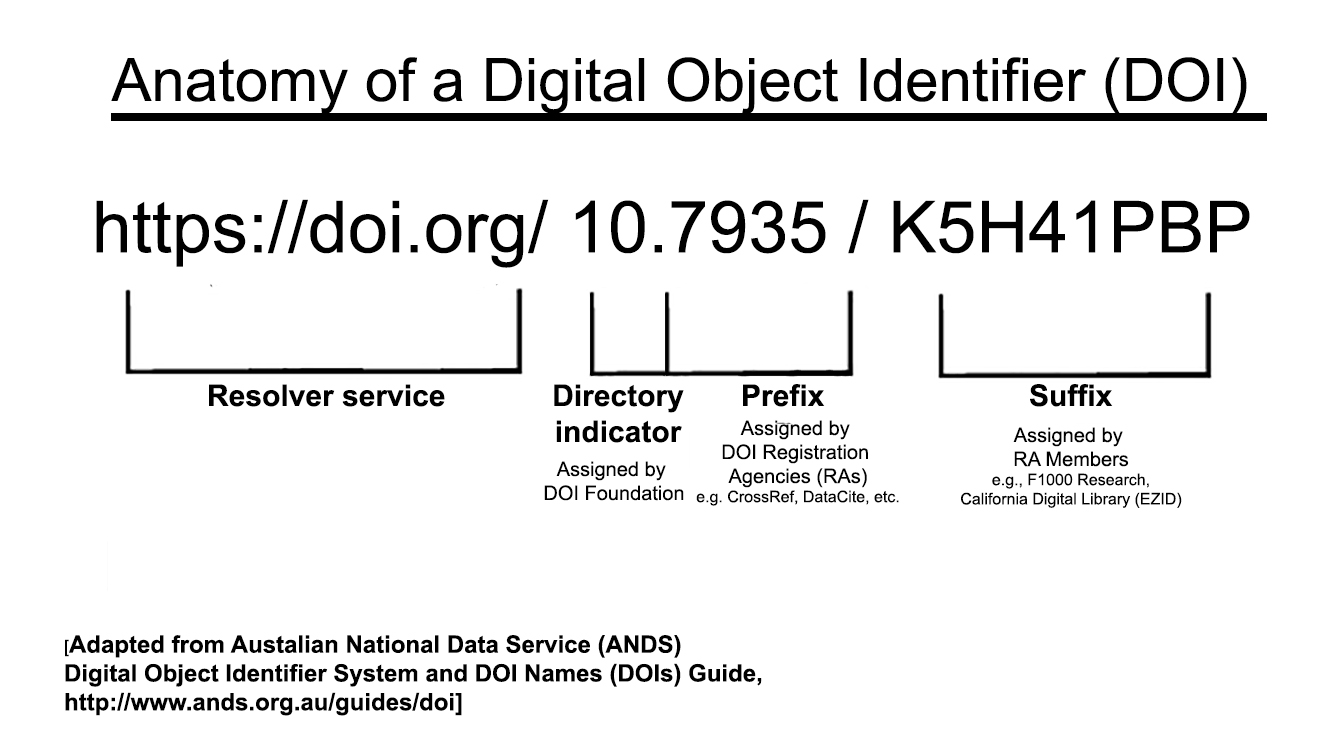
In the example above, the prefix is used by the Australian National Data Service (ANDS), now called the Australia Research Data Commons (ARDC), and the suffix is a unique identifier for an object at Griffith University. DataCite provides DOI display guidance so that they are easy to recognize and use, for both humans and machines.
Exercise - Level Hard 🌶🌶🌶
Upload a dataset in the DEMO DataverseNL repository.
Download the following mock dataset: MOCK DATA.
What is the DOI of your dataset?
Solution
There is no one single answer 🤓
Discussion
Scenario:
You are a researcher of Migration studies, and you conducted personal interviews. So naturally, you want your research data to be visible in your community, given the impact on the topic. Still, obviously, you can’t upload the transcripts, not even in a restricted form, since it’s an ethnographic study.Discuss with your team how it would be best to handle data archiving in situations like this type of data.
Key Points
Data repositories can make research data more discoverable by machines (e.g., Google search engine).
Always aim for a repository that fits your community (e.g., DataverseNL). Else, deposit your dataset on generic repositories (e.g., Zenodo).
If the data is about human subjects or includes demographics, you can always choose to make it private or deposit an aggregated subset.
5. Make machines work for you
Overview
Teaching: 10 min
Exercises: 15 minQuestions
1 What is the difference between Metadata and Rich metadata?
2 How to create a Rich Metadata file?
3 Where to put a Rich Metadata file?
Objectives
The participant will understand the difference between Metadata and Rich Metadata.
The participant will be able to pull Rich Metadata files and harness them.
FAIR principles used for Rich Metadata:
Findable
FM-F2 (Machine-readability of Metadata) → doi.org/10.25504/FAIRsharing.ztr3n9
Interoperable
FM-I1 (Use a Knowledge Representation Language) → doi.org/10.25504/FAIRsharing.jLpL6i
FM-I2 (Use FAIR Vocabularies) → doi.org/10.25504/FAIRsharing.0A9kNV
1. What is the difference between Metadata and Rich metadata?
Metadata is the “data about the data”. It is a detailed description of the Digital Object referring to, for example, the documentation of dataset properties.
For example:
In The Cosmogrid Simulation: Statistical Properties of Small Dark Matter Halos → LINK TO EXAMPLE
We can see how a data source is described for future usage.
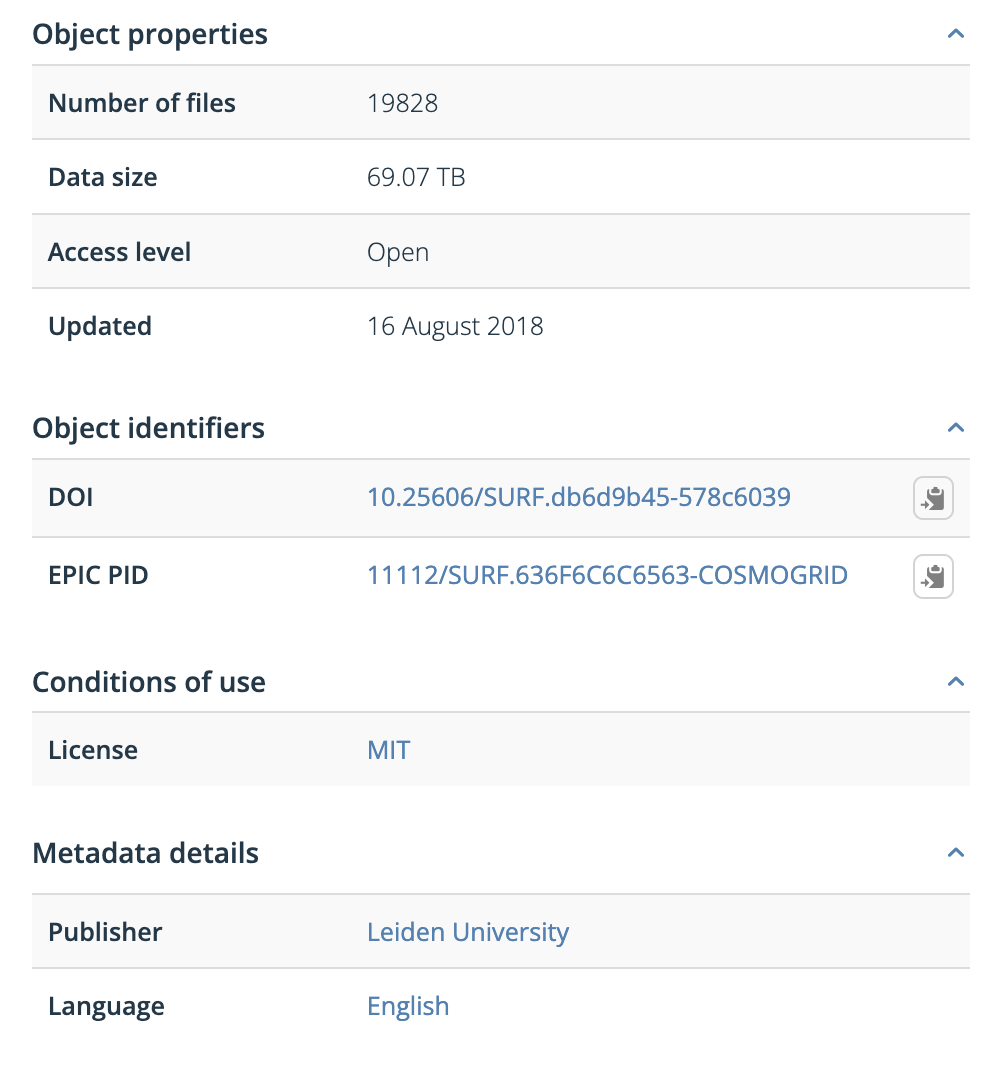
| Metadata Attribute | Example |
|---|---|
| Descriptive Metadata | DOI |
| Structural Metadata | Data Size |
| Administrative Metadata | Publisher |
| Statistical Metadata | Number of files |
Metadata by itself is plain text; to be meaningful for further reuse, it needs to be in a machine-readable format. When data is submitted to a trusted data repository, the machine-readable metadata is generated by the data repository. If the information is not in a repository, a text file with machine-readable metadata can be added as part of the documentation.
Rich Metadata is
- Standardized
- Structured
- Machine- and human-readable
- A subset of documentation
Metadata alone is plain text
There are many examples and resources where you can learn more about metadata. The idea is straightforward: we want to document the scientific data we generate for future use.
More resources
Metadata definition (The Turing Way) → LINK
What is Metadata, and how do I document my data? (CESSDA Training) → LINK
Rich Metadata and indexability by Search Engines (Google) LINK
Video: A walk-through video to describe Metadata in ZENODO
2. How to create a Rich Metadata file?
There are several ways, but the main takeaway is that you don’t need to do it manually. The idea is to fill a form using a tool for Rich Metadata generation (table below) and export it (or copy-paste it) in a machine-readable format such as JSON-LD for interoperability reasons.
| Platform for Rich Metadata generation | Source | Online | Note |
|---|---|---|---|
| Dataverse Export Button | LINK | ✅ | Specific for datasets, it’s the easiest way to get a rich metadata file → RECOMMENDED |
| Metadata wizard | LINK | ✅ | A bit slow, but it is tailored to a generic scientific project |
| JSON-LD Generator Form | LINK | ✅ | Specific to the NanoSafety community, but it can be adapted |
| Steal Our JSON-LD | LINK | ✅ | General use. Ideal for blog posts, tables, videos, and research project websites → RECOMMENDED |
| JSON-LD Schema Generator For SEO | LINK | ✅ | Tailored for SEO, but quite comprehensive |
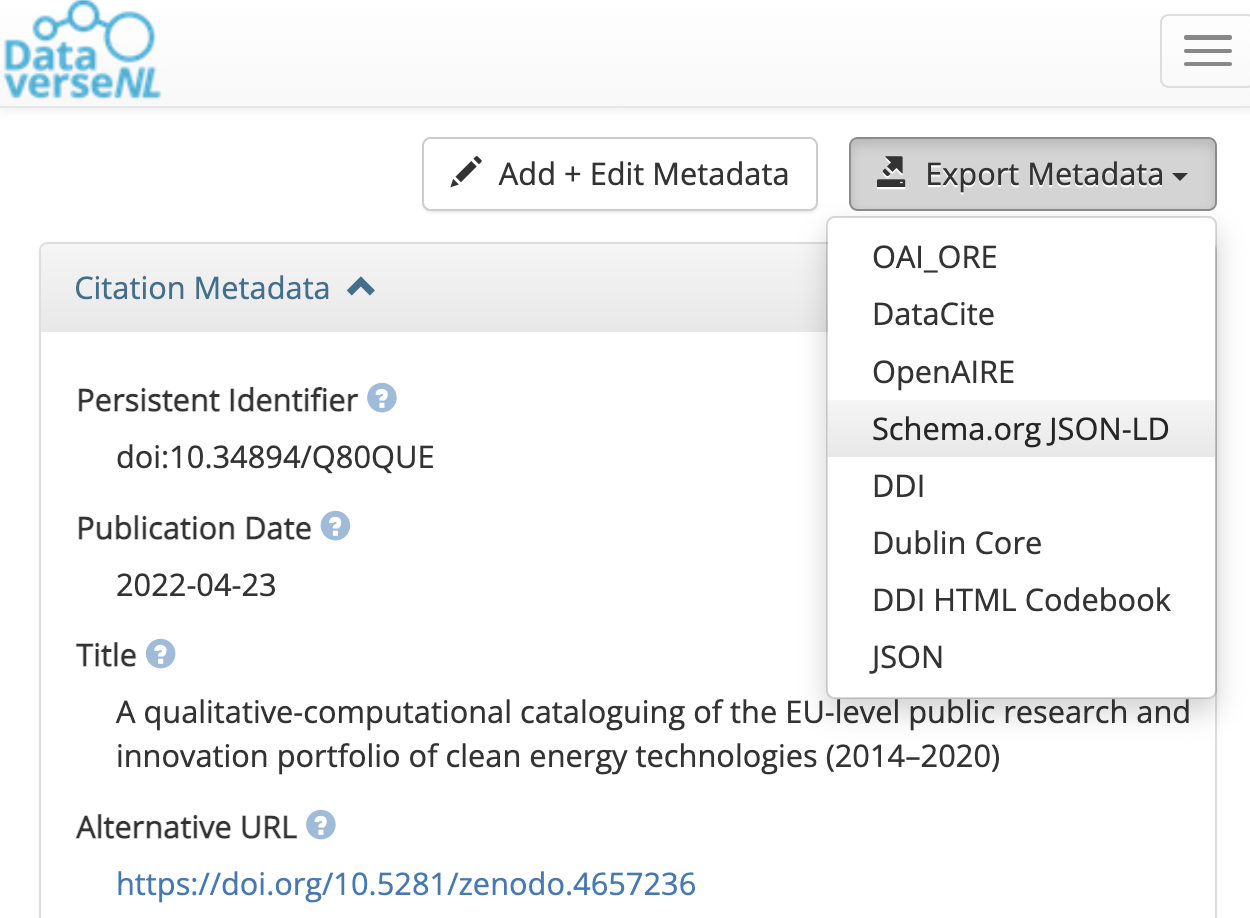
Image: With Dataverse Export Button, you can quickly get your Rich Metadata file
3. Where to put a Rich Metadata file?
A straightforward rule: Everywhere your data is stored.
- In the project’s root folder
- In the data repository
- In the Github repository
- On the project’s webpage
Example:
More and more services are using common schemas such as DataCite’s Metadata Schema or Dublin Core to foster greater use and discovery. A schema provides an overall structure for the metadata and describes core metadata properties. While DataCite’s Metadata Schema is more general, there are discipline-specific schemas such as Data Documentation Initiative (DDI) and Darwin Core.
Thanks to schemas, the process of adding metadata has been standardized to some extent but there is still room for error. For instance, DataCite reports that links between papers and data are still very low. Publishers and authors are missing this opportunity.
Discussion
Scenario:
You are the scientific leader of project consortia. You just learned everything you need to make digital objects discoverable using rich metadata. You are about to create a project’s website.Discuss with your team what is the relation between Rich Metadata files and websites
Key Points
Rich Metadata = Metadata + using FAIR Vocabularies (e.g., Dublin Core) + in an Interoperable format (e.g., JSON-LD)
There are tools for creating Rich Metadata files. Researchers do not have to do it manually. For example: FAIR Metadata Wizard
6. Responsibly reuse
Overview
Teaching: 10 min
Exercises: 15 minQuestions
1 How to cite data when reusing a data source?
2 How do we make sure data will be reused?
Objectives
The participant will understand the importance of data citation.
The participant will learn tools to test discoverability for data to be reused.
FAIR principles used in Data Reusing:
Findable
FM-F1B (Identifier persistence) → doi.org/10.25504/FAIRsharing.TUq8Zj
FM-F4 (Indexed in a Searchable Resource) → doi.org/10.25504/FAIRsharing.Lcws1NReusable
FM-R1.2 (Detailed Provenance) → doi.org/10.25504/FAIRsharing.qcziIV
1. How to cite data when reusing a data source?
“Data Reusing” are activities for recycling existing research data sources.
By default, we should make the research data documentation in citable and reusable formats.
The minimum citation elements recommended by DataCite are:
- Creator
- Publication Year
- Title
- Resource Type or Version
- Publisher
- Digital Object Identifier
For example:
Neff, Roni A.; L. Spiker, Marie; L. Truant, Patricia (2016): Wasted Food: U.S. Consumers’ Reported Awareness, Attitudes, and Behaviors. PLOS ONE. Dataset. https://doi.org/10.1371/journal.pone.0127881
Original dataset at Wasted Food: U.S. Consumers’ Reported Awareness, Attitudes, and Behaviors → LINK TO EXAMPLE
Nowadays, data repositories have a friendly interface on which one can export the data citation directly from the webpage, such as ZENODO, Dataverse, or FigShare.

Citing datasets increases publication visibility by 25%.
When we cite a dataset using a standard format (e.g., recommended by DataCite), then we allow data aggregators to “pick up” on the citations just like publications. Therefore, they immediately become discoverable for scientific sources.
2. How do we make sure data can be reused?
Remember that a dataset or a data source is a digital object. So Digital Objects “live” on the web. Imagine they are like fishes in the sea 🐠🐠. The way to get picked up by a “fisherman” 🎣 i.e. a search engine (e.g. Google), is by describing these Digital Objects with Rich Metadata (Episode 5). Moreover we can check the quality of discoverability of the Digital Objects by conducting automated tests.
There are different available applications to test the discoverability of datasets for future reuse.
For example:
In Google Rich Results search.google.com/test/rich-results, you can test whether a dataset is discoverable by other machines (e.g. Google bots)→ LINK TO EXAMPLE
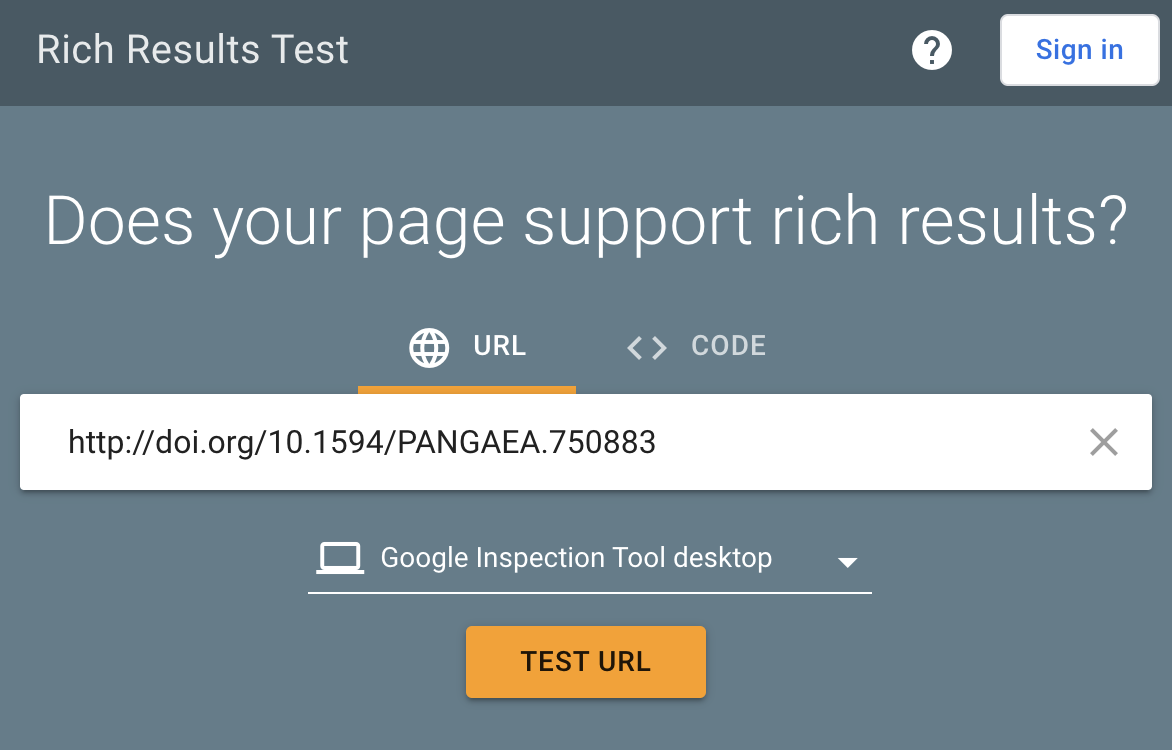
After testing the URL of the data source, you will get the response from the Google bots. We aim to determine if the Google bots have found a structured dataset with the link we provided.
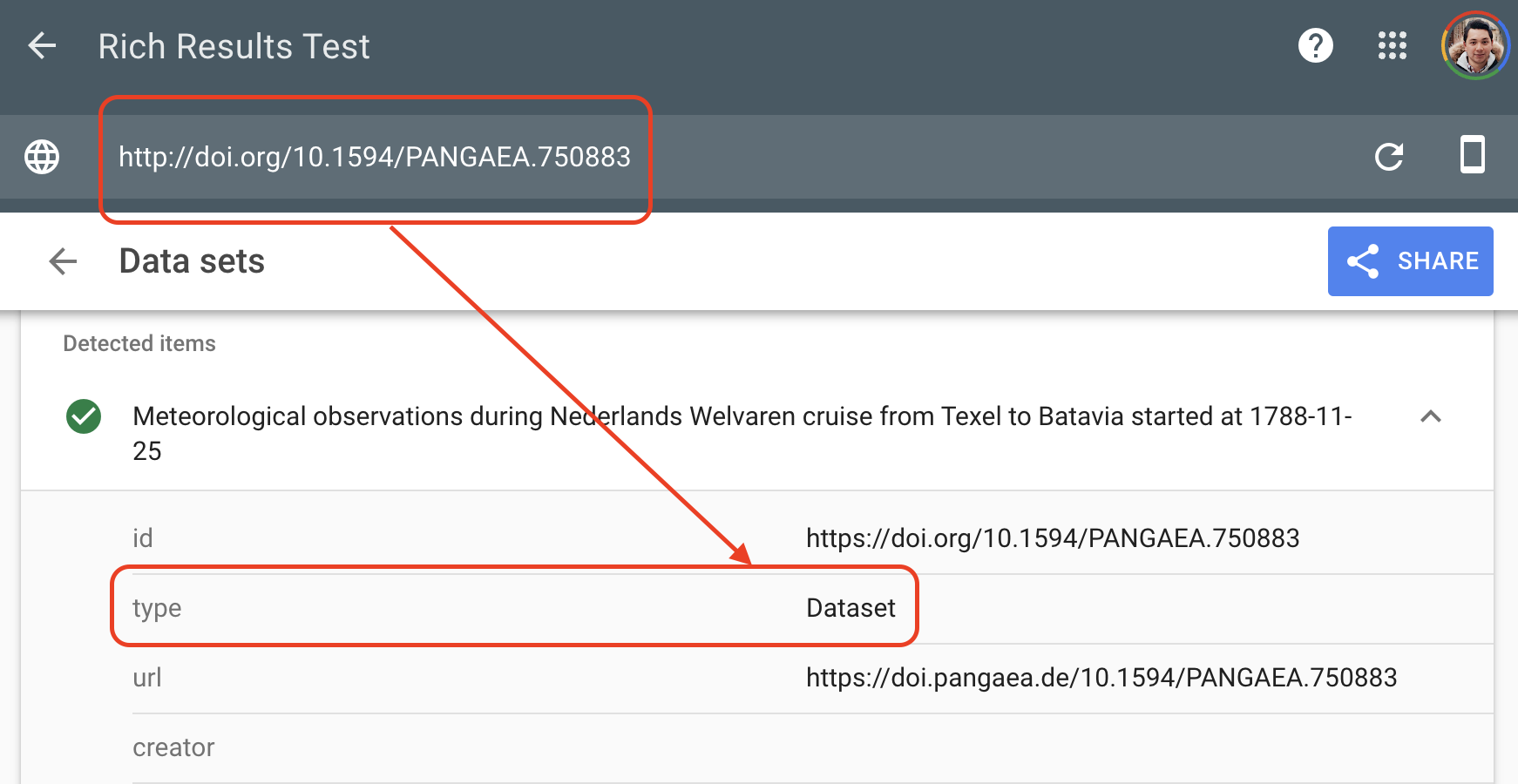
Following the FAIR principles, you ensure Rich Metadata
Rich metadata is necessary to be discoverable on the internet. Without testing it, your data can be virtually invisible on the web
Exercise - Level Easy 🌶
- The following website is a database of crime news related to cultural objects
- Go to news.culturecrime.org
- Perform Google’s rich test on this data source
- You can copy the URL of the browser and put it on the search.google.com/test/rich-results
Question: Did the Google bots find the dataset?Solution
Nope 🙁
They did not. This is a clear example that a data source can be human-friendly but not necessarily machine friendly
If you want to learn more about the Rich Results Test, you can find it here: support.google.com/webmasters/.
The FAIR principles rely in the idea of structured data following Semantic Web guidelines and formats. All search engines (e.g. Google) and data aggregators (e.g. Elsevier)work with the same standards making it easier to discover datasets. They can understand structured data in web pages about datasets using either schema.org, Dataset markup or equivalent structures represented in W3C’s Data Catalog Vocabulary (DCAT) format.
When you have a project website, or project folder accessible to third parties, you must include the Rich Metadata format in the root folder for the data source to be discoverable and therefore Reusable
For example:
<html>
<head>
<title>This Dataset is a FAIR example</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"Dummmy Data",
"description":"This is an example for the Bootcamp",
"url":"https://example.com",
"identifier": ["https://doi.org/XXXXXX",
"https://identifiers.org/XXXX"],
"keywords":[
"DUMMY DATA",
"EXAMPLE FORMAT",
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"funder":{
"@type": "Organization",
"sameAs": "https://example.com",
"name": "NATIONAL FUNDING"
}
}
</script>
</head>
<body>
</body>
</html>
Exercise - Level Easy 🌶
- Visit the dataset you uploaded in the Data Archiving episode
- Download the Rich Metadata file (JSON-LD) format
Question: What similarities do you find with the above example?Solution
The format is JSON-LD: type=”application/ld+json”
The vocabulary is Schema.Org: “@context”:”https://schema.org/”
The type is a Dataset: “@type”:”Dataset”
Discussion
Select datasets from previous examples
Perform FAIR tests in FAIR enough
What can you tel from the FAIR scores
Key Points
Digital Objects (e.g., Datasets) “live” on the web, imagine they are like fishes in the sea 🐠🐠. The way to get picked up by a “fisherman” 🎣 i.e., a search engine (e.g., Google) is by describing these Digital Objects with Rich Metadata.