4. Publish and preserve
Overview
Teaching: 10 min
Exercises: 15 minQuestions
1 What is Data Archiving?
2 What are Data Repositories?
3 What is a DOI, and why is it important?
Objectives
The participant will understand the importance of archiving datasets on trusted data repositories.
The participant will learn the significance of the Digital Object Identifier (DOI).
FAIR principles used in Data Archiving
Findable
FM-F1A (Identifier Uniqueness) → doi.org/10.25504/FAIRsharing.r49beq
FM-F3 (Resource Identifier in Metadata) → doi.org/10.25504/FAIRsharing.o8TYnWAccessible
FM-A2 (Metadata Longevity) → doi.org/10.25504/FAIRsharing.A2W4nz
1. What is Data Archiving?
“Data Archiving” is the practice of placing a digital source in a preservation phase, i.e., the long-term storage of research data.
The various academic journals have different policies regarding how much of their data and methods researchers are required to store in a public archive. Similarly, the major grant-giving institutions have varying attitudes toward public archival of data. In general, publications must have attached sufficient information to allow fellow researchers to replicate and test the research.
2. What are Data Repositories?
Datasets are archived in Data repositories. They are storage locations for digital objects. Data repositories can help make a researcher’s data more discoverable by search engines (e.g., Google) and ultimately lead to potential reuse. Therefore, using storage can lead to increased citations of your work. Data repositories can also serve as backups during rare events where data are lost to the researcher and must be retrieved.
Note
Data Archiving is the long-term storage of research data. Data repositories can help make research data more discoverable by search engines (e.g., Googlebots).
Examples of data repositories:
| Data Repository | About |
|---|---|
| DataverseNL | DataverseNL is a community-specific repository that focuses on Dutch universities and research centers. |
| 4TU Data | 4TU Data is a community repository that was originally created by three technical universities in the Netherlands. |
| PANGEA | PANGEA is a community-specific repository that focuses on Earth & Environmental Science. |
| FigShare | FigShare is an open generic data repository for general purposes; it can store data and other digital objects. |
Just like FigShare, many data repositories are for general use. They provide a low entry barrier to making data Findable, addressing FM-F1A (Identifier Uniqueness) and FM-F3 (Resource Identifier in Metadata).
Recommendations for general-purpose data repositories
ZENODO administrated by CERN
SURF Repository administrated by SURF
DataverseNL administrated by DANS
Quick characteristics of general-purpose repositories:
- Safe — your research is stored safely for the future in a Data Centre for as long as CERN and/or DANS exist.
- Citeable — every upload is assigned a Digital Object Identifier (DOI) to make them citable and trackable.
- No waiting time — Uploads are made available online as soon as you hit publish, and your DOI is registered within seconds.
- Open or closed — Share, e.g., anonymized clinical trial data with only medical professionals via our restricted access mode.
- Versioning — Easily update your dataset with our versioning feature.
- GitHub integration — Easily preserve your GitHub repository in Zenodo.
- Usage statistics — All uploads display standards-compliant usage statistics.
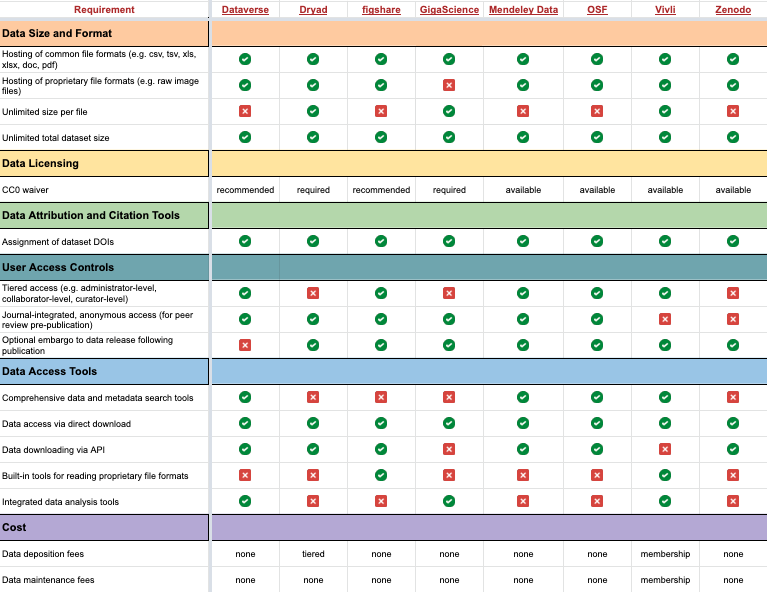 Image: Harvard Medical School, RDM - Data Repositories. Accessed Jul-2022 - *datamanagement.hms.harvard.edu/share/data-repositories
Image: Harvard Medical School, RDM - Data Repositories. Accessed Jul-2022 - *datamanagement.hms.harvard.edu/share/data-repositories
Original Harvard Dataverse
Some public registries where you can find lists of trusted repositories for Data Archiving
Registry of Research Data Repositories (re3data) → re3data.org//
PLOS ONE Recommended Repositories → journals.plos.org/plosone/s/recommended-repositories
NIH Recommended Repositories: → sharing.nih.gov/repositories-for-sharing-scientific-data
Nature - Scientific Data Guidelines: → nature-com.mu.idm.oclc.org/sdata/policies/repositories
OpenDOAR - Directory of Open Access Repositories → v2.sherpa.ac.uk/opendoar/
Exercise - Level Medium 🌶🌶
- Go to dataverse.org and scroll down until you see a map. Respond to the following:
- How many installations of Dataverse are there?
- How many Dataverse installations are in the Netherlands?
- DataverseNL is the data repository hosted by DANS. It supports all higher education institutions in the Netherlands. How many datasets exist now in DataverseNL? (Aug 2022)
Solution
- There are 83 installations worldwide. This means that 83 organizations have a copy of the original Harvard Dataverse layout and have hosted it on their own servers to support researchers.
- There are 3 installations in the Netherlands: DataverseNL, IISH Dataverse, and NIOZ Dataverse.
- There are 6,075.
3. What is a DOI, and why is it important?
The DOI is a common identifier used for academic, professional, and governmental information such as articles, datasets, reports, and other supplemental information. The International DOI Foundation (IDF) is the agency that oversees DOIs. CrossRef and DataCite are two prominent not-for-profit registries that provide services to create or mint DOIs. Both have membership models where their clients are able to mint DOIs distinguished by their prefix. For example, DataCite features a statistics page where you can see registrations by members.
A DOI has three main parts:
- Proxy or DOI resolver service
- Prefix which is unique to the registrant or member
- Suffix, a unique identifier assigned locally by the registrant to an object
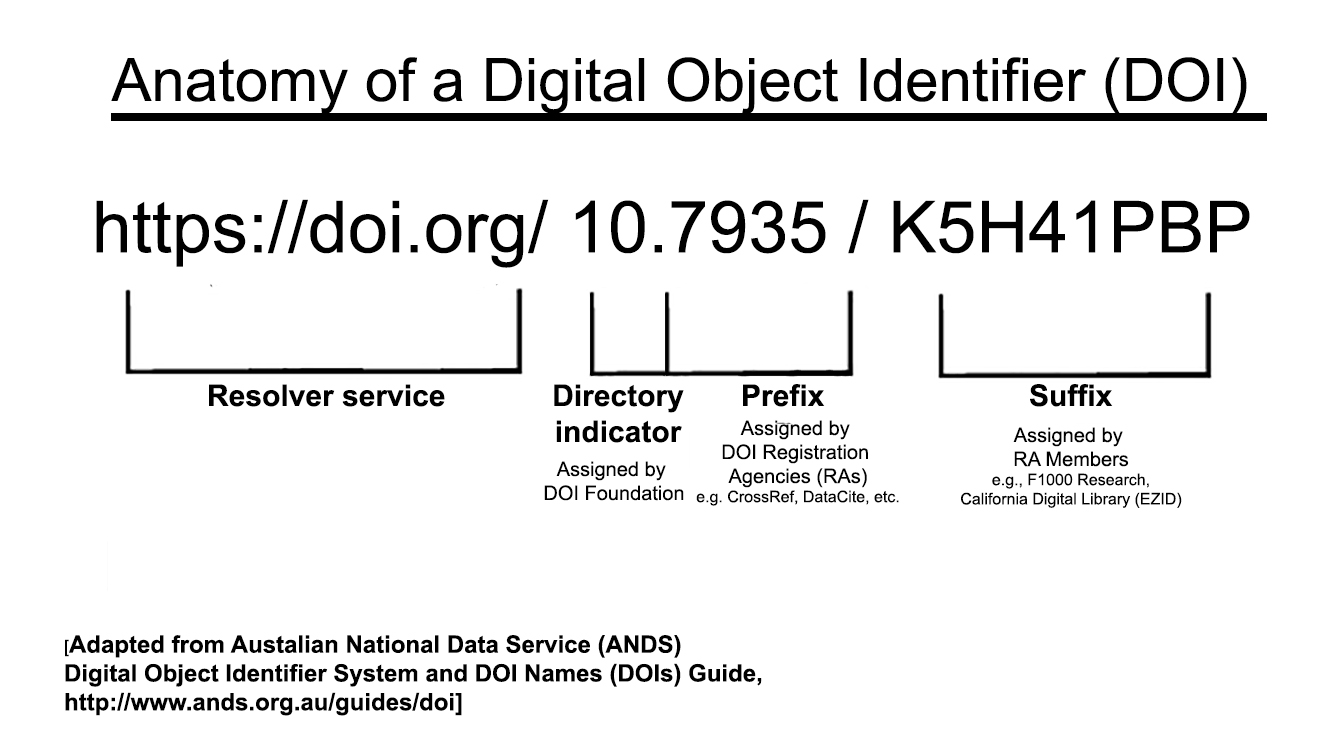
In the example above, the prefix is used by the Australian National Data Service (ANDS), now called the Australia Research Data Commons (ARDC), and the suffix is a unique identifier for an object at Griffith University. DataCite provides DOI display guidance so that they are easy to recognize and use, for both humans and machines.
Exercise - Level Hard 🌶🌶🌶
Upload a dataset in the DEMO DataverseNL repository.
Download the following mock dataset: MOCK DATA.
What is the DOI of your dataset?
Solution
There is no one single answer 🤓
Discussion
Scenario:
You are a researcher of Migration studies, and you conducted personal interviews. So naturally, you want your research data to be visible in your community, given the impact on the topic. Still, obviously, you can’t upload the transcripts, not even in a restricted form, since it’s an ethnographic study.Discuss with your team how it would be best to handle data archiving in situations like this type of data.
Key Points
Data repositories can make research data more discoverable by machines (e.g., Google search engine).
Always aim for a repository that fits your community (e.g., DataverseNL). Else, deposit your dataset on generic repositories (e.g., Zenodo).
If the data is about human subjects or includes demographics, you can always choose to make it private or deposit an aggregated subset.