Imagine you have digitized many books from your collections and made them available via Omeka S in a IIIF-compliant viewer.
Naturally you would also like your users to search the full text contents of these books, as that is something they
cannot do with a physical copy. This blog will describe the steps to make this possible in Omeka S by using a module
that implements the IIIF Content Search API.
Prerequisites
Make sure you have taken the following actions before you start:
- Working Omeka S instance with IIIF modules enabled (see our previous post)
- Digitized book pages uploaded as images (media) to an Omeka S item
- Alto XML file for each page
- Plain text file for each page (or one large text file that holds the contents of all pages)
Install Advanced Search & Solr modules
These modules add search functionality to your Omeka S instance. The Solr adapter makes sure that all contents are indexed
to increase the search experience.
Installation instructions can be found in the module’s readme files:
Install IiifSearch module
This module implements the IIIF Content Search API and lets you search within items (book pages) and highlights the search
result in the image viewer.
Install this module and configure the xml and application/alto+xml settings using the instructions in our
previous post.
This module extracts text from media and store it as item metadata, so you can search for it.
Install ExtractText following the instructions from the module’s readme.
Add Alto XML files to Omeka S item
Alto XML files contain text OCR and layout (pixel coordinates) of digitized pages. Popular OCR software applications are able to
save the OCR’ed material as Alto XML. The IiifSearch module natively supports Alto XML and is able to use it in the IIIF
Content Search API.
Manual upload:
- Login to the Omeka S admin panel
- Go to Items
- Edit the item of choice
- Open the Media tab
- Upload the Alto XML files in the same order as the book pages (image files)
- Save the item.
Automated upload
Please note that, when working with larger books, it might be more useful to use bulk upload methods like CSV Import
or Omeka’s REST API.
Add plain text file(s) to Omeka S item
The plain text (.txt) files contain the full text for the page or the entire book.
These will be processed by the ExtractText module, the content will be concatenated and stored as item metadata in the
field extracttext:extracted_text. Subsequently, they are being indexed by Solr to make full text search across your
entire Omeka S instance possible.
Manual upload:
- Login to the Omeka S admin panel
- Go to Items
- Edit the item of choice
- Open the Media tab
- Upload the plain text files in the same order as the book pages (image files)
- Save the item.
Automated upload
Please note that, when working with larger books, it might be more useful to use bulk upload methods like CSV Import
or Omeka’s REST API.
Search across items
Since the contents of the extracttext:extracted_text item metadata field are indexed by Advanced Search and Solr a user
can simply type some terms in the search field to find all items that match the search query.
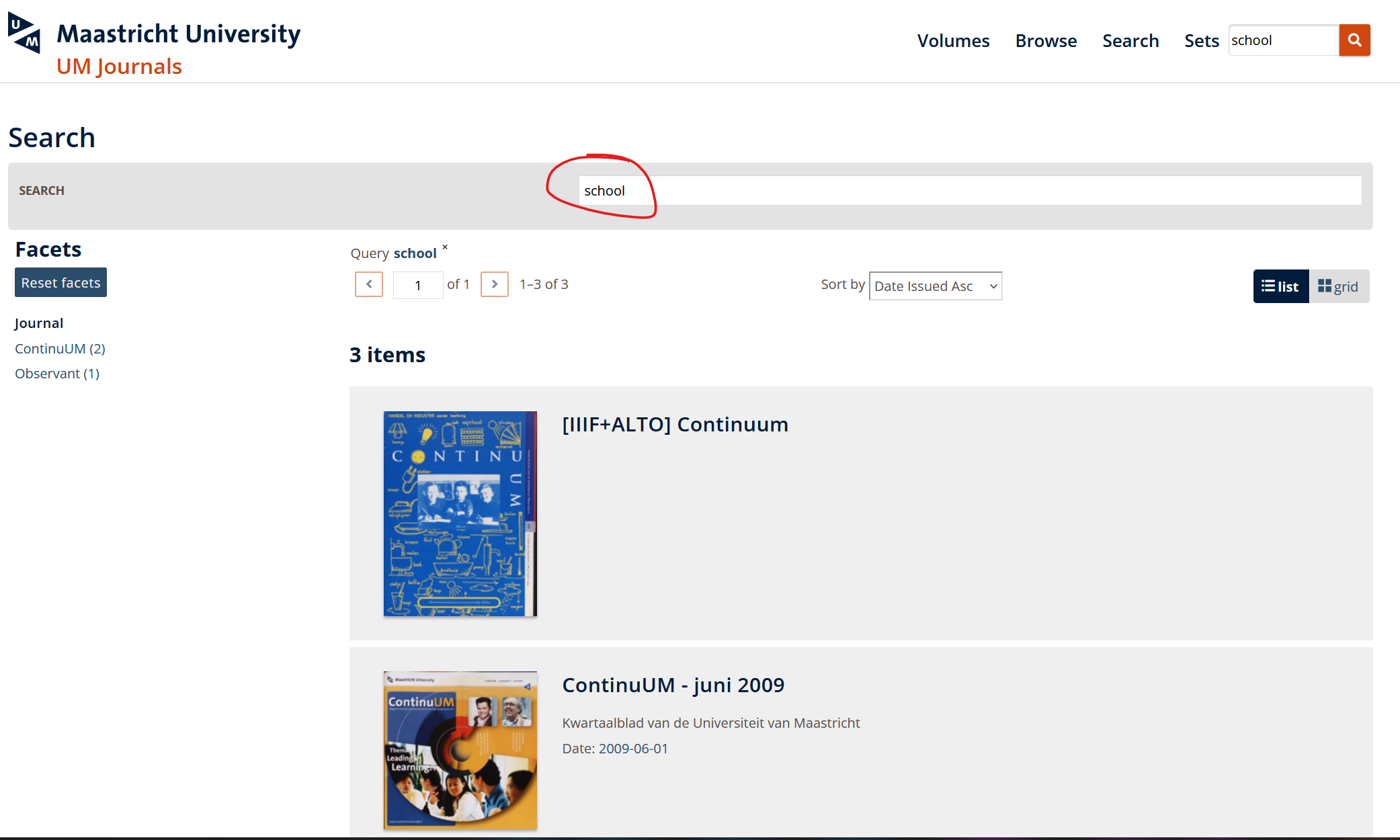
In the example below, the user has searched for the word “school”. The result set contains 3 items in which the word “school” appears.
Search within items
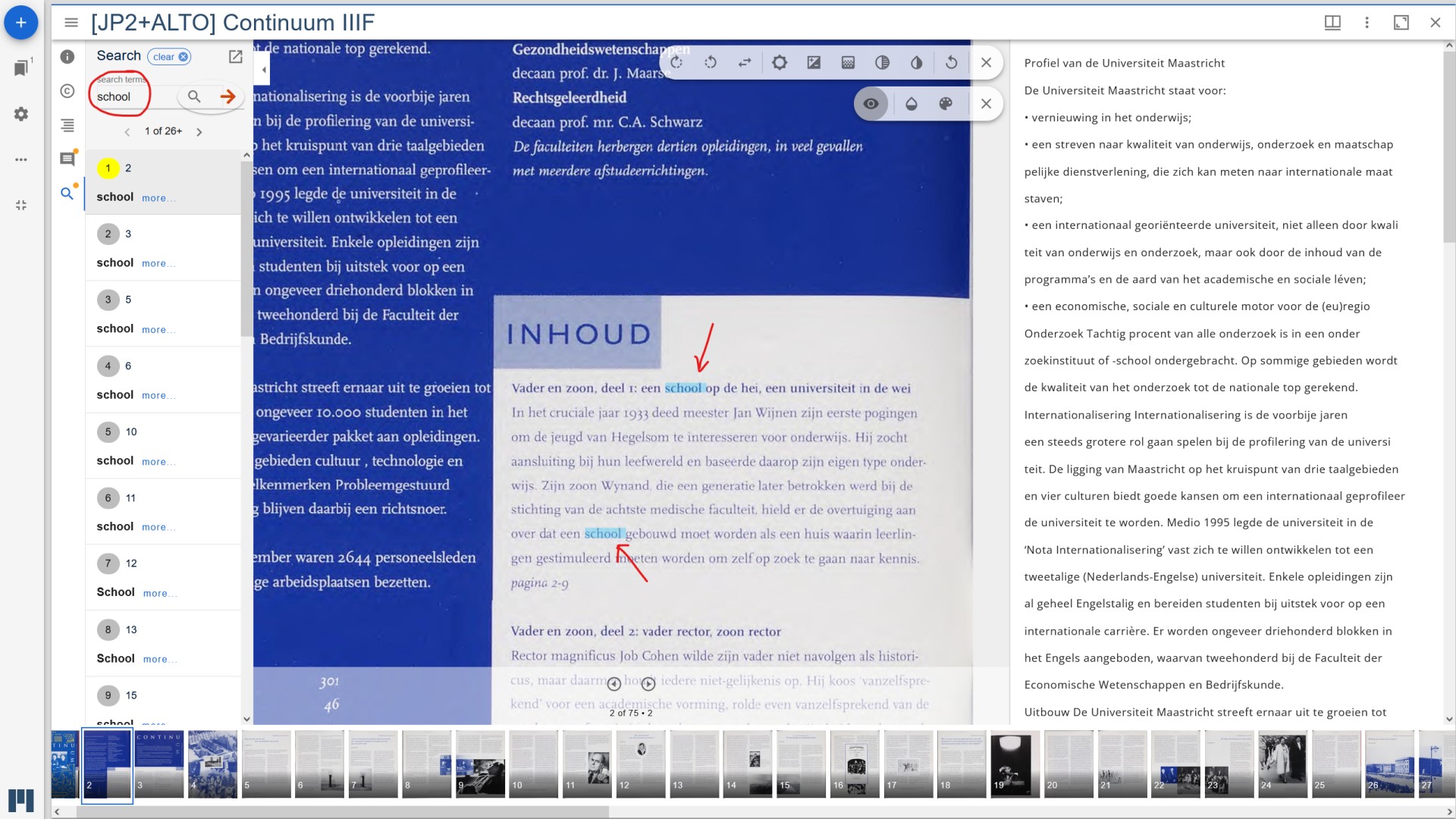
Searching within items is performed by the IiifSearch module that is integrated with the image viewer. Continuing on the
example above, the user opens an item from the “Search across” result, clicks the search icon (magnifying glass) and
enters the same search term to find all results in this particular book. Search results are highlighted on the page
because of the pixel coordinates provided by the Alto XML file.
That’s all for this blog. Happy searching!
Maastricht University Library
Library Systems and Development
